Искусственный интеллект, нейронные сети, машинное обучение — что на самом деле означают все эти нынче популярные понятия? Для большинства непосвященных людей, коим и являюсь я сам, они всегда казались чем-то фантастическим, но на самом деле суть их лежит на поверхности. У меня давно созревала идея написать простым языком об искусственных нейронных сетях. Узнать самому и рассказать другим, что представляют собой эта технология, как она работают, рассмотреть ее историю и перспективы. В этой статье я постарался не залезать в дебри, а просто и популярно рассказать об этом перспективном направление в мире высоких технологий.
Искусственный интеллект, нейронные сети, машинное обучение - что на самом деле означают все эти нынче популярные понятия? Для большинства непосвященных людей, коим являюсь и я сам, они всегда казались чем-то фантастическим, но на самом деле суть их лежит на поверхности. У меня давно созревала идея написать простым языком об искусственных нейронных сетях. Узнать самому и рассказать другим, что представляет собой эта технология, как она работает, рассмотреть ее историю и перспективы. В этой статье я постарался не залезать в дебри, а просто и популярно рассказать об этом перспективном направление в мире высоких технологий.
Впервые понятие искусственных нейронных сетей (ИНС) возникло при попытке смоделировать процессы головного мозга. Первым серьезным прорывом в этой сфере можно считать создание модели нейронных сетей МакКаллока-Питтса в 1943 году. Учеными впервые была разработана модель искусственного нейрона. Ими также была предложена конструкция сети из этих элементов для выполнения логических операций. Но самое главное, учеными было доказано, что подобная сеть способна обучаться.

Следующим важным шагом стала разработка Дональдом Хеббом первого алгоритма вычисления ИНС в 1949 году, который стал основополагающем на несколько последующих десятилетий. В 1958 году Фрэнком Розенблаттом был разработан парцептрон - система, имитирующая процессы головного мозга. В свое время технология не имела аналогов и до сих пор является основополагающей в нейронных сетях. В 1986 году практически одновременно, независимо друг от друга американскими и советскими учеными был существенно доработан основополагающий метод обучения многослойного перцептрона . В 2007 году нейронные сети перенесли второе рождение. Британский информатик Джеффри Хинтоном впервые разработал алгоритм глубокого обучения многослойных нейронных сетей, который сейчас, например, используется для работы беспилотных автомобилей.
В общем смысле слова, нейронные сети - это математические модели, работающие по принципу сетей нервных клеток животного организма. ИНС могут быть реализованы как в программируемые, так и в аппаратные решения. Для простоты восприятия нейрон можно представить, как некую ячейку, у которой имеется множество входных отверстий и одно выходное. Каким образом многочисленные входящие сигналы формируются в выходящий, как раз и определяет алгоритм вычисления. На каждый вход нейрона подаются действенные значения, которые затем распространяются по межнейронным связям (синопсисам). У синапсов есть один параметр - вес, благодаря которому входная информация изменяется при переходе от одного нейрона к другому. Легче всего принцип работы нейросетей можно представить на примере смешения цветов. Синий, зеленый и красный нейрон имеют разные веса. Информация того нейрона, вес которого больше будет доминирующей в следующем нейроне.

Сама нейросеть представляет собой систему из множества таких нейронов (процессоров). По отдельности эти процессоры достаточно просты (намного проще, чем процессор персонального компьютера), но будучи соединенными в большую систему нейроны способны выполнять очень сложные задачи.
В зависимости от области применения нейросеть можно трактовать по-разному, Например, с точки зрения машинного обучения ИНС представляет собой метод распознавания образов. С математической точки зрения - это многопараметрическая задача. С точки зрения кибернетики - модель адаптивного управления робототехникой. Для искусственного интеллекта ИНС - это основополагающее составляющее для моделирования естественного интеллекта с помощью вычислительных алгоритмов.
Основным преимуществом нейросетей над обычными алгоритмами вычисления является их возможность обучения. В общем смысле слова обучение заключается в нахождении верных коэффициентов связи между нейронами, а также в обобщении данных и выявлении сложных зависимостей между входными и выходными сигналами. Фактически, удачное обучение нейросети означает, что система будет способна выявить верный результат на основании данных, отсутствующих в обучающей выборке.

И какой бы многообещающей не была бы эта технология, пока что ИНС еще очень далеки от возможностей человеческого мозга и мышления. Тем не менее, уже сейчас нейросети применяются во многих сферах деятельности человека. Пока что они не способны принимать высокоинтеллектуальные решения, но в состоянии заменить человека там, где раньше он был необходим. Среди многочисленных областей применения ИНС можно отметить: создание самообучающихся систем производственных процессов, беспилотные транспортные средства, системы распознавания изображений, интеллектуальные охранные системы, робототехника, системы мониторинга качества, голосовые интерфейсы взаимодействия, системы аналитики и многое другое. Такое широкое распространение нейросетей помимо прочего обусловлено появлением различных способов ускорения обучения ИНС.

На сегодняшний день рынок нейронных сетей огромен - это миллиарды и миллиарды долларов. Как показывает практика, большинство технологий нейросетей по всему миру мало отличаются друг от друга. Однако применение нейросетей - это очень затратное занятие, которое в большинстве случаев могут позволить себе только крупные компании. Для разработки, обучения и тестирования нейронных сетей требуются большие вычислительные мощности, очевидно, что этого в достатке имеется у крупных игроков на рынке ИТ. Среди основных компаний, ведущих разработки в этой области можно отметить подразделение Google DeepMind, подразделение Microsoft Research, компании IBM, Facebook и Baidu.
Конечно, все это хорошо: нейросети развиваются, рынок растет, но пока что главная задача так и не решена. Человечеству не удалось создать технологию, хотя бы приближенную по возможностям к человеческому мозгу. Давайте рассмотрим основные различия между человеческим мозгом и искусственными нейросетями.
Самым главным отличием, которое в корне меняет принцип и эффективность работы системы - это разная передача сигналов в искусственных нейронных сетях и в биологической сети нейронов. Дело в том, что в ИНС нейроны передают значения, которые являются действительными значениями, то есть числами. В человеческом мозге осуществляется передача импульсов с фиксированной амплитудой, причем эти импульсы практически мгновенные. Отсюда вытекает целый ряд преимуществ человеческой сети нейронов.

Во-первых, линии связи в мозге намного эффективнее и экономичнее, чем в ИНС. Во-вторых, импульсная схема обеспечивает простоту реализации технологии: достаточно использование аналоговых схем вместо сложных вычислительных механизмов. В конечном счете, импульсные сети защищены от звуковых помех. Действенные числа подвержены влиянию шумов, в результате чего повышается вероятность возникновения ошибки.
Безусловно, в последнее десятилетие произошел настоящий бум развития нейронных сетей. В первую очередь это связано с тем, что процесс обучения ИНС стал намного быстрее и проще. Также стали активно разрабатываться так называемые «предобученные» нейросети, которые позволяют существенно ускорить процесс внедрения технологии. И если пока что рано говорить о том, смогут ли когда-то нейросети полностью воспроизвести возможности человеческого мозга, вероятность того, что в ближайшее десятилетие ИНС смогут заменить человека на четверти существующих профессий все больше становится похожим на правду.
Искусственная нейронная сеть — совокупность нейронов, взаимодействующих друг с другом. Они способны принимать, обрабатывать и создавать данные. Это настолько же сложно представить, как и работу человеческого мозга. Нейронная сеть в нашем мозгу работает для того, чтобы вы сейчас могли это прочитать: наши нейроны распознают буквы и складывают их в слова.
Искусственная нейронная сеть - это подобие мозга. Изначально она программировалась с целью упростить некоторые сложные вычислительные процессы. Сегодня у нейросетей намного больше возможностей. Часть из них находится у вас в смартфоне. Ещё часть уже записала себе в базу, что вы открыли эту статью. Как всё это происходит и для чего, читайте далее.
Людям очень хотелось понять, откуда у человека разум и как работает мозг. В середине прошлого века канадский нейропсихолог Дональд Хебб это понял. Хебб изучил взаимодействие нейронов друг с другом, исследовал, по какому принципу они объединяются в группы (по-научному - ансамбли) и предложил первый в науке алгоритм обучения нейронных сетей.
Спустя несколько лет группа американских учёных смоделировала искусственную нейросеть, которая могла отличать фигуры квадратов от остальных фигур.
Исследователи выяснили, нейронная сеть - это совокупность слоёв нейронов, каждый из которых отвечает за распознавание конкретного критерия: формы, цвета, размера, текстуры, звука, громкости и т. д. Год от года в результате миллионов экспериментов и тонн вычислений к простейшей сети добавлялись новые и новые слои нейронов. Они работают по очереди. Например, первый определяет, квадрат или не квадрат, второй понимает, квадрат красный или нет, третий вычисляет размер квадрата и так далее. Не квадраты, не красные и неподходящего размера фигуры попадают в новые группы нейронов и исследуются ими.
Учёные развили нейронные сети так, что те научились различать сложные изображения, видео, тексты и речь. Типов нейронных сетей сегодня очень много. Они классифицируются в зависимости от архитектуры - наборов параметров данных и веса этих параметров, некой приоритетности. Ниже некоторые из них.
Нейроны делятся на группы, каждая группа вычисляет заданную ей характеристику. В 1993 году французский учёный Ян Лекун показал миру LeNet 1 - первую свёрточную нейронную сеть, которая быстро и точно могла распознавать цифры, написанные на бумаге от руки. Смотрите сами:
Сегодня свёрточные нейронные сети используются в основном с мультимедиными целями: они работают с графикой, аудио и видео.
Нейроны последовательно запоминают информацию и строят дальнейшие действия на основе этих данных. В 1997 году немецкие учёные модифицировали простейшие рекуррентные сети до сетей с долгой краткосрочной памятью. На их основе затем были разработаны сети с управляемыми рекуррентными нейронами.
Сегодня с помощью таких сетей пишутся и переводятся тексты, программируются боты, которые ведут осмысленные диалоги с человеком, создаются коды страниц и программ.
Использование такого рода нейросетей - это возможность анализировать и генерировать данные, составлять базы и даже делать прогнозы.
В 2015 году компания SwiftKey выпустила первую в мире клавиатуру, работающую на рекуррентной нейросети с управляемыми нейронами. Тогда система выдавала подсказки в процессе набранного текста на основе последних введённых слов. В прошлом году разработчики обучили нейросеть изучать контекст набираемого текста, и подсказки стали осмысленными и полезными:

Такие нейронные сети способны понимать, что находится на изображении, и описывать это. И наоборот: рисовать изображения по описанию. Ярчайший пример продемонстрировал Кайл Макдональд, взяв нейронную сеть на прогулку по Амстердаму. Сеть мгновенно определяла, что находится перед ней. И практически всегда точно:

1. Skype внедрил возможность синхронного перевода уже для 10 языков. Среди которых, на минуточку, есть русский и японский - одни из самых сложных в мире. Конечно, качество перевода требует серьёзной доработки, но сам факт того, что уже сейчас вы можете общаться с коллегами из Японии по-русски и быть уверенными, что вас поймут, вдохновляет.
2. Яндекс на базе нейронных сетей создал два поисковых алгоритма: «Палех» и «Королёв». Первый помогал найти максимально релевантные сайты для низкочастотных запросов. «Палех» изучал заголовки страниц и сопоставлял их смысл со смыслом запросов. На основе «Палеха» появился «Королёв». Этот алгоритм оценивает не только заголовок, но и весь текстовый контент страницы. Поиск становится всё точнее, а владельцы сайтов разумнее начинают подходить к наполнению страниц.
3. Коллеги сеошников из Яндекса создали музыкальную нейросеть: она сочиняет стихи и пишет музыку. Нейрогруппа символично называется Neurona, и у неё уже есть первый альбом:

4. У Google Inbox с помощью нейросетей осуществляется ответ на сообщение. Развитие технологий идет полный ходом, и сегодня сеть уже изучает переписку и генерирует возможные варианты ответа. Можно не тратить время на печать и не бояться забыть какую-нибудь важную договорённость.

5. YouTube использует нейронные сети для ранжирования роликов, причём сразу по двум принципам: одна нейронная сеть изучает ролики и реакции аудитории на них, другая проводит исследование пользователей и их предпочтений. Именно поэтому рекомендации YouTube всегда в тему.
6. Facebook активно работает над DeepText AI - программой для коммуникаций, которая понимает жаргон и чистит чатики от обсценной лексики.
7. Приложения вроде Prisma и Fabby, созданные на нейросетях, создают изображения и видео:

Colorize восстанавливает цвета на чёрно-белых фото (удивите бабушку!).

MakeUp Plus подбирает для девушек идеальную помаду из реального ассортимента реальных брендов: Bobbi Brown, Clinique, Lancome и YSL уже в деле.

8.
Apple и Microsoft постоянно апгрейдят свои нейронные Siri и Contana. Пока они только исполняют наши приказы, но уже в ближайшем будущем начнут проявлять инициативу: давать рекомендации и предугадывать наши желания.
Самообучающиеся нейросети могут заменить людей: начнут с копирайтеров и корректоров. Уже сейчас роботы создают тексты со смыслом и без ошибок. И делают это значительно быстрее людей. Продолжат с сотрудниками кол-центров, техподдержки, модераторами и администраторами пабликов в соцсетях. Нейронные сети уже умеют учить скрипт и воспроизводить его голосом. А что в других сферах?
Нейросеть внедрят в спецтехнику. Комбайны будут автопилотироваться, сканировать растения и изучать почву, передавая данные нейросети. Она будет решать - полить, удобрить или опрыскать от вредителей. Вместо пары десятков рабочих понадобятся от силы два специалиста: контролирующий и технический.
В Microsoft сейчас активно работают над созданием лекарства от рака. Учёные занимаются биопрограммированием - пытаются оцифрить процесс возникновения и развития опухолей. Когда всё получится, программисты смогут найти способ заблокировать такой процесс, по аналогии будет создано лекарство.
Маркетинг максимально персонализируется. Уже сейчас нейросети за секунды могут определить, какому пользователю, какой контент и по какой цене показать. В дальнейшем участие маркетолога в процессе сведётся к минимуму: нейросети будут предсказывать запросы на основе данных о поведении пользователя, сканировать рынок и выдавать наиболее подходящие предложения к тому моменту, как только человек задумается о покупке.
Ecommerce будет внедрён повсеместно. Уже не потребуется переходить в интернет-магазин по ссылке: вы сможете купить всё там, где видите, в один клик. Например, читаете вы эту статью через несколько лет. Очень вам нравится помада на скрине из приложения MakeUp Plus (см. выше). Вы кликаете на неё и попадаете сразу в корзину. Или смотрите видео про последнюю модель Hololens (очки смешанной реальности) и тут же оформляете заказ прямо из YouTube.
Едва ли не в каждой области будут цениться специалисты со знанием или хотя бы пониманием устройства нейросетей, машинного обучения и систем искусственного интеллекта. Мы будем существовать с роботами бок о бок. И чем больше мы о них знаем, тем спокойнее нам будет жить.
P. S.
Зинаида Фолс - нейронная сеть Яндекса, пишущая стихи. Оцените произведение, которое машина написала, обучившись на Маяковском (орфография и пунктуация сохранены):
« Это »
это
всего навсего
что-то
в будущем
и мощь
у того человека
есть на свете все или нет
это кровьа вокруг
по рукам
жиреет
слава у
земли
с треском в клюве
Впечатляет, правда?
В наши дни возрастает необходимость в системах, которые способны не только выполнять однажды запрограммированную последовательность действий над заранее определенными данными, но и способны сами анализировать вновь поступающую информацию, находить в ней закономерности, производить прогнозирование и т.д. В этой области приложений самым лучшим образом зарекомендовали себя так называемые нейронные сети – самообучающиеся системы, имитирующие деятельность человеческого мозга. Рассмотрим подробнее структуру искусственных нейронных сетей (НС) и их применение в конкретных задачах.
Несмотря на большое разнообразие вариантов нейронных сетей, все они имеют общие черты. Так, все они, так же, как и мозг человека, состоят из большого числа связанных между собой однотипных элементов – нейронов , которые имитируют нейроны головного мозга. На рис. 1 показана схема нейрона.
Из рисунка видно, что искусственный нейрон, так же, как и живой, состоит из синапсов, связывающих входы нейрона с ядром; ядра нейрона, которое осуществляет обработку входных сигналов и аксона, который связывает нейрон с нейронами следующего слоя. Каждый синапс имеет вес, который определяет, насколько соответствующий вход нейрона влияет на его состояние. Состояние нейрона определяется по формуле
$S =\sum \limits_{i=1}^{n} \,x_iw_i$, (1)
$\sum \limits_{k=1}^{N} k^2$, (1)
n – число входов нейрона
x i – значение i-го входа нейрона
w i – вес i-го синапса.
Затем определяется значение аксона нейрона по формуле
$Y = f\,(S)$, (2)
Где f – некоторая функция, которая называется активационной . Наиболее часто в качестве активационной функции используется так называемый сигмоид , который имеет следующий вид:
$f\,(x) = \frac{1}{1\,+\,\mbox e^{-ax}}$, (3)
Основное достоинство этой функции в том, что она дифференцируема на всей оси абсцисс и имеет очень простую производную:
$f"\,(x) = \alpha f(x)\,\bigl(1\,-\,f\,(x)\bigr)$, (4)
При уменьшении параметра a сигмоид становится более пологим, вырождаясь в горизонтальную линию на уровне 0,5 при a=0. При увеличении a сигмоид все больше приближается к функции единичного скачка.

Нейронные сети обратного распространения – это мощнейший инструмент поиска закономерностей, прогнозирования, качественного анализа. Такое название – сети обратного распространения (back propagation) они получили из-за используемого алгоритма обучения, в котором ошибка распространяется от выходного слоя к входному, т. е. в направлении, противоположном направлению распространения сигнала при нормальном функционировании сети.
Нейронная сеть обратного распространения состоит из нескольких слоев нейронов, причем каждый нейрон слоя i связан с каждым нейроном слоя i+1 , т. е. речь идет о полносвязной НС.
В общем случае задача обучения НС сводится к нахождению некой функциональной зависимости Y=F(X) где X – входной, а Y – выходной векторы. В общем случае такая задача, при ограниченном наборе входных данных, имеет бесконечное множество решений. Для ограничения пространства поиска при обучении ставится задача минимизации целевой функции ошибки НС, которая находится по методу наименьших квадратов:
$E\,(w) = \frac{1}{2}\sum \limits_{j=1}^{p} \, {(y_i\,-\,d_i)}^2$, (5)
y j – значение j-го выхода нейросети,
d j – целевое значение j-го выхода,
p – число нейронов в выходном слое.
Обучение нейросети производится методом градиентного спуска, т. е. на каждой итерации изменение веса производится по формуле:
$\Delta\,w_{ij} = -\,\eta\,\cdot\,\frac{\partial\,E}{\partial\,w_{ij}}$, (6)
где h – параметр, определяющий скорость обучения.
$\frac{\partial\,E}{\partial\,w_{ij}} = \frac{\partial\,E}{\partial\,y_i}\,\cdot\,\frac{dy_i}{dS_j}\,\cdot\,\frac{\partial\,S_j}{\partial\,w_{ij}}$, (7)
y j – значение выхода j-го нейрона,
S j – взвешенная сумма входных сигналов, определяемая по формуле (1).
При этом множитель
$\frac{\partial\,S_j}{\partial\,w_{ij}} = x_i$, (8)
x i – значение i-го входа нейрона.
$\frac{\partial\,E}{\partial\,y_j} = \sum \limits_{k}^{} \frac{\partial\,E}{\partial\,y_k}\,\cdot\,\frac{dy_k}{dS_k}\,\cdot\,\frac{\partial\,S_k}{\partial\,y_j} = \sum \limits_{k}^{} \frac{\partial\,E}{\partial\,y_k}\,\cdot\,\frac{dy_k}{dS_k}\,\cdot\,w_{jk}^{(n+1)}$, (9)
k – число нейронов в слое n+1 .
Введем вспомогательную переменную
$\delta_j^{(n)}= \frac{\partial\,E}{\partial\,y_j}\,\cdot\,\frac{dy_j}{dS_j}$, (10)
Тогда мы сможем определить рекурсивную формулу для определения n -ного слоя, если нам известно следующего (n+1) -го слоя.
$\delta_j^{(n)}= \biggl[ \sum \limits_{k}^{} \delta_k^{(n+1)}\,\cdot\,w_{jk}^{(n+1)}\biggr]\,\cdot\,\frac{dy_j}{dS_j}$, (11)
Нахождение же для последнего слоя НС не представляет трудности, так как нам известен целевой вектор, т. е. вектор тех значений, которые должна выдавать НС при данном наборе входных значений.
$\delta_j^{(N)}= \bigl(y_i^{(N)}-\,d_i\bigr)\,\cdot\,\frac{dy_j}{dS_j}$, (12)
И наконец запишем формулу (6) в раскрытом виде
$\Delta w_{ij}^{(n)}= -\,\eta\,\cdot\,\delta_j^{(n)}\,\cdot\,x_i^n$, (13)
Рассмотрим теперь полный алгоритм обучения нейросети:
$w_{ij}^{(n)}\,(t) = w_{ij}^{(n)}\,(t\,-\,1) \,+\,\Delta w_{ij}^{(n)}\,(t)$, (14)
На этапе 2 сети поочередно в случайном порядке предъявляются вектора из обучающей последовательности.
Простейший метод градиентного спуска, рассмотренный выше, очень неэффективен в случае, когда производные по различным весам сильно отличаются. Это соответствует ситуации, когда значение функции S для некоторых нейронов близка по модулю к 1 или когда модуль некоторых весов много больше 1. В этом случае для плавного уменьшения ошибки надо выбирать очень маленькую скорость обучения, но при этом обучение может занять непозволительно много времени.
Простейшим методом усовершенствования градиентного спуска является введение момента m , когда влияние градиента на изменение весов изменяется со временем. Тогда формула (13) примет вид
$\Delta w_{ij}^{(n)}\,(t) = -\,\eta\,\cdot\,\delta_j^{(n)}\,\cdot\,x_i^n\,+\,\mu\,\Delta w_{ij}^{(n)}\,(t\,-\,1)$ , (13.1)
Дополнительным преимуществом от введения момента является способность алгоритма преодолевать мелкие локальные минимумы.
Основное отличие НС в том, что в них все входные и выходные параметры представлены в виде чисел с плавающей точкой обычно в диапазоне . В то же время данные предметной области часто имеют другое кодирование. Так, это могут быть числа в произвольном диапазоне, даты, символьные строки. Таким образом данные о проблеме могут быть как количественными, так и качественными. Рассмотрим сначала преобразование качественных данных в числовые, а затем рассмотрим способ преобразования входных данных в требуемый диапазон.
Качественные данные мы можем разделить на две группы: упорядоченные (ординальные) и неупорядоченные. Для рассмотрения способов кодирования этих данных мы рассмотрим задачу о прогнозировании успешности лечения какого-либо заболевания. Примером упорядоченных данных могут, например, являться данные, например, о дополнительных факторах риска при данном заболевании.
А также возможным примером может быть, например, возраст больного:
Опасность каждого фактора возрастает в таблицах при движении слева направо.
В первом случае мы видим, что у больного может быть несколько факторов риска одновременно. В таком случае нам необходимо использовать такое кодирование, при котором отсутствует ситуация, когда разным комбинациям факторов соответствует одно и то же значение. Наиболее распространен способ кодирования, когда каждому фактору ставится в соответствие разряд двоичного числа. 1 в этом разряде говорит о наличии фактора, а 0 о его отсутствии. Параметру нет можно поставить в соответствии число 0. Таким образом для представления всех факторов достаточно 4-х разрядного двоичного числа. Таким образом число 1010 2 = 10 10 означает наличие у больного гипертонии и употребления алкоголя, а числу 0000 2 соответствует отсутствие у больного факторов риска. Таким образом факторы риска будут представлены числами в диапазоне .
Во втором случае мы также можем кодировать все значения двоичными весами, но это будет нецелесообразно, т.к. набор возможных значений будет слишком неравномерным. В этом случае более правильным будет установка в соответствие каждому значению своего веса, отличающегося на 1 от веса соседнего значения. Так, число 3 будет соответствовать возрасту 50-59 лет. Таким образом возраст будет закодирован числами в диапазоне .
В принципе аналогично можно поступать и для неупорядоченных данных, поставив в соответствие каждому значению какое-либо число. Однако это вводит нежелательную упорядоченность, которая может исказить данные, и сильно затруднить процесс обучения. В качестве одного из способов решения этой проблемы можно предложить поставить в соответствие каждому значению одного из входов НС. В этом случае при наличии этого значения соответствующий ему вход устанавливается в 1 или в 0 при противном случае. К сожалению, данный способ не является панацеей, ибо при большом количестве вариантов входного значения число входов НС разрастается до огромного количества. Это резко увеличит затраты времени на обучение. В качестве варианта обхода этой проблемы можно использовать несколько другое решение. В соответствие каждому значению входного параметра ставится бинарный вектор, каждый разряд которого соответствует отдельному входу НС.
Литература
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace . Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств - это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле - это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.

Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.

Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex"a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон - это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга - нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.

В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей - как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х - это наше входное изображение, Y - это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.

Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.

Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
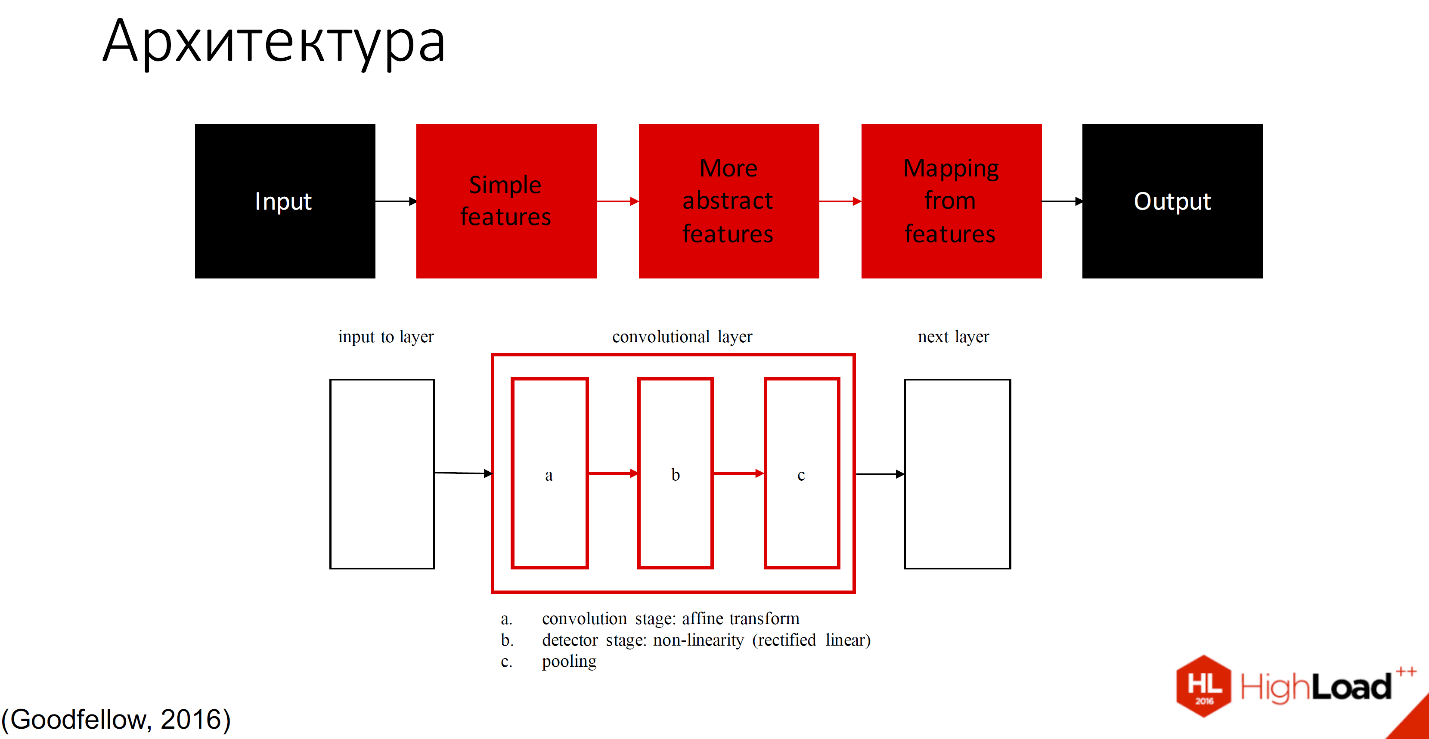
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений - один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.

Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP - многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.

Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.

С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети - это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.

На примере этого изображения рассмотрим, что делает каждая из задач.

Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль - всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace - это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый - это идентификация, поиск лица по базе данных. Второе - это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection - это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям - нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition - аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду - после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке - одной из самых простых эмоций - есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.

В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически - мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение - это максимально быстрый исход игры с максимально большим счетом.
Справа вверху - последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым - нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память - то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.

Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных - это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet"е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите - самый последний кадр - реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги - все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить - семантическая сегментация 3D изображений в медицине. Вообще medical imaging - это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.

Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
НЕЙРО́ННЫЕ СЕ́ТИ искусственные, многослойные высокопараллельные (т. е. с большим числом независимо параллельно работающих элементов) логические структуры, составленные из формальных нейронов. Начало теории нейронных сетей и нейрокомпьютеров положила работа американских нейрофизиологов У. Мак-Каллока и У. Питтса «Логическое исчисление идей, относящихся к нервной деятельности» (1943), в которой они предложили математическую модель биологического нейрона. Среди основополагающих работ следует выделить модель Д. Хэбба, который в 1949 г. предложил закон обучения, явившийся стартовой точкой для алгоритмов обучения искусственных нейронных сетей. На дальнейшее развитие теории нейронной сети существенное влияние оказала монография американского нейрофизиолога Ф. Розенблатта «Принципы нейродинамики», в которой он подробно описал схему перцептрона (устройства, моделирующего процесс восприятия информации человеческим мозгом). Его идеи получили развитие в научных работах многих авторов. В 1985–86 гг. теория нейронных сетей получила «технологический импульс», вызванный возможностью моделирования нейронных сетей на появившихся в то время доступных и высокопроизводительных персональных компьютерах . Теория нейронной сети продолжает достаточно активно развиваться в начале 21 века. По оценкам специалистов, в ближайшее время ожидается значительный технологический рост в области проектирования нейронных сетей и нейрокомпьютеров. За последние годы уже открыто немало новых возможностей нейронных сетей, а работы в данной области вносят существенный вклад в промышленность, науку и технологии, имеют большое экономическое значение.
Потенциальными областями применения искусственных нейронных сетей являются те, где человеческий интеллект малоэффективен, а традиционные вычисления трудоёмки или физически неадекватны (т. е. не отражают или плохо отражают реальные физические процессы и объекты). Актуальность применения нейронных сетей (т. е. нейрокомпьютеров) многократно возрастает, когда появляется необходимость решения плохо формализованных зада ч. Основные области применения нейронных сетей: автоматизация процесса классификации, автоматизация прогнозирования, автоматизация процесса распознавания, автоматизация процесса принятия решений; управление, кодирование и декодирование информации; аппроксимация зависимостей и др.
С помощью нейронных сетей успешно решается важная задача в области телекоммуникаций – проектирование и оптимизация сетей связи (нахождение оптимального пути трафика между узлами). Кроме управления маршрутизацией потоков, нейронные сети используются для получения эффективных решений в области проектирования новых телекоммуникационных сетей.
Распознавание речи – одна из наиболее популярных областей применения нейронных сетей.
Ещё одна область – управление ценами и производством (потери от неоптимального планирования производства часто недооцениваются). Поскольку спрос и условия реализации продукции зависят от времени, сезона, курсов валют и многих других факторов, то и объём производства должен гибко варьироваться с целью оптимального использования ресурсов (нейросетевая система обнаруживает сложные зависимости между затратами на рекламу, объёмами продаж, ценой, ценами конкурентов, днём недели, сезоном и т. д.). В результате использования системы осуществляется выбор оптимальной стратегии производства с точки зрения максимизации объёма продаж или прибыли.
При анализе потребительского рынка (маркетинг), когда обычные (классические) методы прогнозирования отклика потребителей могут быть недостаточно точны, используется прогнозирующая нейросетевая система с адаптивной архитектурой нейросимулятора.
Исследование спроса позволяет сохранить бизнес компании в условиях конкуренции, т. е. поддерживать постоянный контакт с потребителями через «обратную связь». Крупные компании проводят опросы потребителей, позволяющие выяснить, какие факторы являются для них решающими при покупке данного товара или услуги, почему в некоторых случаях предпочтение отдаётся конкурентам и какие товары потребитель хотел бы увидеть в будущем. Анализ результатов такого опроса – достаточно сложная задача, так как существует большое число коррелированных параметров. Нейросетевая система позволяет выявлять сложные зависимости между факторами спроса, прогнозировать поведение потребителей при изменении маркетинговой политики, находить наиболее значимые факторы и оптимальные стратегии рекламы, а также очерчивать сегмент потребителей, наиболее перспективный для данного товара.
В медицинской диагностике нейронные сети применяются, например, для диагностики слуха у грудных детей. Система объективной диагностики обрабатывает зарегистрированные «вызванные потенциалы» (отклики мозга), проявляющиеся в виде всплесков на электроэнцефалограмме, в ответ на звуковой раздражитель, синтезируемый в процессе обследования. Обычно для уверенной диагностики слуха ребёнка опытному эксперту-аудиологу необходимо провести до 2000 тестов, что занимает около часа. Система на основе нейронной сети способна с той же достоверностью определить уровень слуха уже по 200 наблюдениям в течение всего нескольких минут, причём без участия квалифицированного персонала.
Нейронные сети применяются также для прогнозирования краткосрочных и долгосрочных тенденций в различных областях (финансовой, экономической, банковской и др.).
Нервная система и мозг человека состоят из нейронов, соединённых между собой нервными волокнами. Нервные волокна способны передавать электрические импульсы между нейронами. Все процессы передачи раздражений от нашей кожи, ушей и глаз к мозгу, процессы мышления и управления действиями – всё это реализовано в живом организме как передача электрических импульсов между нейронами.
Биологический нейрон (Cell) имеет ядро (Nucleus), а также отростки нервных волокон двух типов (рис. 1) – дендриты (Dendrites), по которым принимаются импульсы (Carries signals in), и единственный аксон (Axon), по которому нейрон может передавать импульс (Carries signals away). Аксон контактирует с дендритами других нейронов через специальные образования – синапсы (Synapses), которые влияют на силу передаваемого импульса. Структура, состоящая из совокупности большого количества таких нейронов, получила название биологической (или естественной) нейронной сети.
Появление формального нейрона во многом обусловлено изучением биологических нейронов. Формальный нейрон (далее – нейрон) является основой любой искусственной нейронной сети. Нейроны представляют собой относительно простые, однотипные элементы, имитирующие работу нейронов мозга. Каждый нейрон характеризуется своим текущим состоянием по аналогии с нервными клетками головного мозга, которые могут быть возбуждены и заторможены. Искусственный нейрон, так же как и его естественный прототип, имеет группу синапсов (входов ), которые соединены с выходами других нейронов, а также аксон – выходную связь данного нейрона, откуда сигнал возбуждения или торможения поступает на синапсы других нейронов.
Формальный нейрон представляет собой логический элемент с $N$ входами, ($N+1$ ) весовыми коэффициентами, сумматором и нелинейным преобразователем. Простейший формальный нейрон, осуществляющий логическое преобразование $y = \text{sign}\sum_{i=0}^{N}a_ix_i$ входных сигналов (которыми, напр., являются выходные сигналы др. формальных нейронов Н. с.) в выходной сигнал, представлен на рис. 1.
Здесь $y$ – значение выхода формального нейрона; $a_i$ – весовые коэффициенты; $x_i$ – входные значения формального нейрона ($x_i∈\left \{0,1\right \},\; x_0=1$ ). Процесс вычисления выходного значения формального нейрона представляет собой движение потока данных и их преобразование. Сначала данные поступают на блок входа формального нейрона, где происходит умножение исходных данных на соответствующие весовые коэффициенты, т. н. синоптические веса (в соответствии с синапсами биологических нейронов). Весовой коэффициент является мерой, которая определяет, насколько соответствующее входное значение влияет на состояние формального нейрона. Весовые коэффициенты могут изменяться в соответствии с обучающими примерами, архитектурой Н. с., правилами обучения и др. Полученные (при умножении) значения преобразуются в сумматоре в одно числовое значение $g$ (посредством суммирования). Затем для определения выхода формального нейрона в блоке нелинейного преобразования (реализующего передаточную функцию) $g$ сравнивается с некоторым числом (порогом). Если сумма больше значения порога, формальный нейрон генерирует сигнал, в противном случае сигнал будет нулевым или тормозящим. В данном формальном нейроне применяется нелинейное преобразование$$\text{sign}(g)= \begin{cases} 0,\; g < 0 \\ 1,\; g ⩾ 0 \end{cases},\quad \text{где}\,\,g = \sum_{i=0}^N a_i x_i.$$
Выбор структуры нейронной сети осуществляется в соответствии с особенностями и сложностью задачи. Теоретически число слоёв и число нейронов в каждом слое нейронной сети может быть произвольным, однако фактически оно ограничено ресурсами компьютера или специализированной микросхемы, на которых обычно реализуется нейронная сеть. При этом если в качестве активационной функции для всех нейронов сети используется функция единичного скачка, нейронная сеть называется многослойным персептроно м.
На рис. 3 показана общая схема многослойной нейронной сети с последовательными связями. Высокий параллелизм обработки достигается путём объединения большого числа формальных нейронов в слои и соединения определённым образом различных нейронов между собой.
В общем случае в эту структуру могут быть введены перекрёстные и обратные связи с настраиваемыми весовыми коэффициентами (рис. 4).
Нейронные сети являются сложными нелинейными системами с огромным числом степеней свободы. Принцип, по которому они обрабатывают информацию, отличается от принципа, используемого в компьютерах на основе процессоров с фон-неймановской архитектурой – с логическим базисом И, ИЛИ, НЕ (см. Дж. фон Нейман , Вычислительная машина ). Вместо классического программирования (как в традиционных вычислительных системах) применяется обучение нейронной сети, которое сводится, как правило, к настройке весовых коэффициентов с целью оптимизации заданного критерия качества функционирования нейронной сети.
Нейросетевым алгоритмом решения задач называется вычислительная процедура, полностью или по большей части реализованная в виде нейронной сети той или иной структуры (например, многослойная нейронная сеть с последовательными или перекрёстными связями между слоями формальных нейронов) с соответствующим алгоритмом настройки весовых коэффициентов. Основой разработки нейросетевого алгоритма является системный подход, при котором процесс решения задачи представляется как функционирование во времени некоторой динамической системы. Для её построения необходимо определить: объект, выступающий в роли входного сигнала нейронной сети; объект, выступающий в роли выходного сигнала нейронной сети (например, непосредственно решение или некоторая его характеристика); желаемый (требуемый) выходной сигнал нейронной сети; структуру нейронной сети (число слоёв, связи между слоями, объекты, служащие весовыми коэффициентами); функцию ошибки системы (характеризующую отклонение желаемого выходного сигнала нейронной сети от реального выходного сигнала); критерий качества системы и функционал её оптимизации, зависящий от ошибки; значение весовых коэффициентов (например, определяемых аналитически непосредственно из постановки задачи, с помощью некоторых численных методов или процедуры настройки весовых коэффициентов нейронной сети).
Количество и тип формальных нейронов в слоях, а также число слоёв нейронов выбираются исходя из специфики решаемых задач и требуемого качества решения. Нейронная сеть в процессе настройки на решение конкретной задачи рассматривается как многомерная нелинейная система, которая в итерационном режиме целенаправленно ищет оптимум некоторого функционала, количественно определяющего качество решения поставленной задачи. Для нейронных сетей, как многомерных нелинейных объектов управления, формируются алгоритмы настройки множества весовых коэффициентов. Основные этапы исследования нейронной сети и построения алгоритмов настройки (адаптации) их весовых коэффициентов включают: исследование характеристик входного сигнала для различных режимов работы нейронной сети (входным сигналом нейронной сети является, как правило, входная обрабатываемая информация и указание так называемого «учител я» нейронной сети); выбор критериев оптимизации (при вероятностной модели внешнего мира такими критериями могут быть минимум средней функции риска, максимум апостериорной вероятности, в частности при наличии ограничений на отдельные составляющие средней функции риска); разработку алгоритма поиска экстремумов функционалов оптимизации (например, для реализации алгоритмов поиска локальных и глобального экстремумов); построение алгоритмов адаптации коэффициентов нейронной сети; анализ надёжности и методов диагностики нейронной сети и др.
Необходимо отметить, что введение обратных связей и, как следствие, разработка алгоритмов настройки их коэффициентов в 1960–80 годы имели чисто теоретический смысл, т. к. не было практических задач, адекватных таким структурам. Лишь в конце 1980-х – начале 1990-х годов стали появляться такие задачи и простейшие структуры с настраиваемыми обратными связями для их решения (так называемые рекуррентные нейронные сети). Разработчики в области нейросетевых технологий занимались не только созданием алгоритмов настройки многослойных нейронных сетей и нейросетевыми алгоритмами решения различных задач, но и наиболее эффективными (на текущий момент развития технологии электроники) аппаратными эмуляторами (особые программы, которые предназначены для запуска одной системы в оболочке другой) нейросетевых алгоритмов. В 1960-е годы, до появления микропроцессора, наиболее эффективными эмуляторами нейронных сетей были аналоговые реализации разомкнутых нейронных сетей с разработанными алгоритмами настройки на универсальных ЭВМ (иногда системы на адаптивных элементах с аналоговой памятью). Такой уровень развития электроники делал актуальным введение перекрёстных связей в структуры нейронных сетей. Это приводило к значительному уменьшению числа нейронов в нейронной сети при сохранении качества решения задачи (например, дискриминантной способности при решении задач распознавания образов). Исследования 1960–70-х годов в области оптимизации структур нейронных сетей с перекрёстными связями наверняка найдут развитие при реализации мемристорных нейронных систем [мемристор (memristor, от memory – память, и resistor – электрическое сопротивление), пассивный элемент в микроэлектронике, способный изменять своё сопротивление в зависимости от протекавшего через него заряда], с учётом их специфики в части аналого-цифровой обработки информации и весьма значительного количества настраиваемых коэффициентов. Специфические требования прикладных задач определяли некоторые особенности структур нейронных сетей с помощью алгоритмов настройки: континуум (от лат. continuum – непрерывное, сплошное) числа классов, когда указание «учителя» системы формируется в виде непрерывного значения функции в некотором диапазоне изменения; континуум решений многослойной нейронной сети, формируемый выбором континуальной функции активации нейрона последнего слоя; континуум числа признаков, формируемый переходом в пространстве признаков от представления выходного сигнала в виде $N$ -мерного вектора вещественных чисел к вещественной функции в некотором диапазоне изменения аргумента; континуум числа признаков, как следствие, требует специфической программной и аппаратной реализации нейронной сети; вариант континуума признаков входного пространства был реализован в задаче распознавания периодических сигналов без преобразования их с помощью аналого-цифрового преобразователя (АЦП) на входе системы, и реализацией аналого-цифровой многослойной нейронной сети; континуум числа нейронов в слое; реализация многослойных нейронных сетей с континуумом классов и решений проводится выбором соответствующих видов функций активации нейронов последнего слоя.
В таблице показан систематизированный набор вариантов алгоритмов настройки многослойных нейронных сетей в пространстве «Входной сигнал – пространство решений». Представлено множество вариантов характеристик входных и выходных сигналов нейронных сетей, для которых справедливы алгоритмы настройки коэффициентов, разработанных российской научной школой в 1960–70 годах. Сигнал на вход нейронной сети описывается количеством классов (градаций) образов, представляющих указания «учителя». Выходной сигнал нейронной сети представляет собой количественное описание пространства решений. В таблице дана классификация вариантов функционирования нейронных сетей для различных видов входного сигнала (2 класса, $K$ классов, континуум классов) и различных вариантов количественного описания пространства решений (2 решения, $K_p$ решений, континуум решений). Цифрами 1, 7, 8 представлены конкретные варианты функционирования нейронных сетей.
Таблица. Набор вариантов алгоритмов настройки
| Пространство(число) решений | Входной сигнал |
||||
| 2 класса | $K$ классов | Континуум классов | |||
| 2 | 1 | 7 | 8 | ||
| $K_p$ | $K_p=3$ | 3а | $K\lt K_p$ | 9 | 10 |
| $K = K_p$ | 2 | ||||
| $K_p =\text{const}$ | 3б | $K\gt K_p$ | 4 | ||
| Континуум | 5 | 6 | 11 | ||
Основными преимуществами нейронных сетей как логического базиса алгоритмов решения сложных задач являются: инвариантность (неизменность, независимость) методов синтеза нейронных сетей от размерности пространства признаков; возможность выбора структуры нейронных сетей в значительном диапазоне параметров в зависимости от сложности и специфики решаемой задачи с целью достижения требуемого качества решения; адекватность текущим и перспективным технологиям микроэлектроники; отказоустойчивость в смысле его небольшого, а не катастрофического изменения качества решения задачи в зависимости от числа вышедших из строя элементов.
Нейронные сети явились в теории управления одним из первых примеров перехода от управления простейшими линейными стационарными системами к управлению сложными нелинейными, нестационарными, многомерными, многосвязными системами. Во второй половине 1960-х годов родилась методика синтеза нейронных сетей, которая развивалась и успешно применялась в течение последующих почти пятидесяти лет. Общая структура этой методики представлена на рис. 5.
Вероятностная модель окружающего мира является основой нейросетевых технологий. Подобная модель – основа математической статистики. Нейронные сети возникли как раз в то время, когда экспериментаторы, использующие методы математической статистики, задали себе вопрос: «А почему мы обязаны описывать функции распределения входных случайных сигналов в виде конкретных аналитических выражений (нормальное распределение, распределение Пуассона и т. д.)? Если это правильно и на это есть какая-то физическая причина, то задача обработки случайных сигналов становится достаточно простой».
Специалисты по нейросетевым технологиям сказали: «Мы ничего не знаем о функции распределения входных сигналов, мы отказываемся от необходимости формального описания функции распределения входных сигналов, даже если сузим класс решаемых задач. Мы считаем функции распределения входных сигналов сложными, неизвестными и будем решать частные конкретные задачи в условиях подобной априорной неопределённости (т. е. неполноты описания; нет информации и о возможных результатах)». Именно поэтому нейронные сети в начале 1960-х годов эффективно применялись при решении задач распознавания образов. Причём задача распознавания образов трактовалась как задача аппроксимации многомерной случайной функции, принимающей $K$ значений, где $K$ – число классов образов.
Ниже отмечены некоторые режимы работы многослойных нейронных сетей, определяемые характеристиками случайных входных сигналов, для которых ещё в конце 1960-х годов были разработаны алгоритмы настройки коэффициентов.
Очевидно, что функционирование нейронной сети, т. е. действия, которые она способна выполнять, зависит от величин синоптических связей. Поэтому, задавшись структурой нейронной сети, отвечающей определённой задаче, разработчик должен найти оптимальные значения для всех весовых коэффициентов $w$ . Этот этап называется обучением нейронной сети, и от того, насколько качественно он будет выполнен, зависит способность сети решать во время эксплуатации поставленные перед ней проблемы. Важнейшими параметрами обучения являются: качество подбора весовых коэффициентов и время, которое необходимо затратить на обучение. Как правило, два этих параметра связаны между собой обратной зависимостью и их приходится выбирать на основе компромисса. В настоящее время все алгоритмы обучения нейронных сетей можно разделить на два больших класса: «с учителем» и «без учителя».
При всей недостаточности априорной информации о функциях распределения входных сигналов игнорирование некоторой полезной информации может привести к потере качества решения задачи. Это в первую очередь касается априорных вероятностей появления классов. Были разработаны алгоритмы настройки многослойных нейронных сетей с учётом имеющейся информации об априорных вероятностях появления классов. Это имеет место в таких задачах, как распознавание букв в тексте, когда для данного языка вероятность появления каждой буквы известна и эту информацию необходимо использовать при построении алгоритма настройки коэффициентов многослойной нейронной сети.
Нейронной сети предъявляются значения как входных, так и выходных параметров, и она по некоторому внутреннему алгоритму подстраивает веса своих синаптических связей. Обучение «с учителем» предполагает, что для каждого входного вектора существует целевой вектор, представляющий собой требуемый выход. В общем случае квалификация «учителя» может быть различной для различных классов образов. Вместе они называются представительской или обучающей выборко й. Обычно нейронная сеть обучается на некотором числе таких выборок. Предъявляется выходной вектор, вычисляется выход нейронной сети и сравнивается с соответствующим целевым вектором, разность (ошибка) с помощью обратной связи подаётся в нейронную сеть, и веса изменяются в соответствии с алгоритмом, стремящимся минимизировать ошибку. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
В задачах распознавания образов, как правило, по умолчанию квалификация «учителя» является полной, т.е. вероятность правильного отнесения «учителем» образов к тому или иному классу равна единице. На практике при наличии косвенных измерений это зачастую не соответствует действительности, например в задачах медицинской диагностики, когда при верификации (проверке) архива медицинских данных, предназначенных для обучения, вероятность отнесения этих данных к тому или иному заболеванию не равна единице. Введение понятия квалификации «учителя» позволило разработать единые алгоритмы настройки коэффициентов многослойных нейронных сетей для режимов обучения, обучения «с учителем», обладающим конечной квалификацией, и самообучения (кластеризации), когда при наличии $K$ или двух классов образов квалификация «учителя» (вероятность отнесения образов к тому или иному классу) равна $\frac {1} {K}$ или 1 / 2 . Введение понятия квалификации «учителя» в системах распознавания образов позволило чисто теоретически рассмотреть режимы «вредительства» системе, когда ей сообщается заведомо ложное (с различной степенью ложности) отнесение образов к тому или иному классу. Данный режим настройки коэффициентов многослойной нейронной сети пока не нашёл практического применения.
Кластеризация (самообучение, обучение «без учителя») – это частный режим работы многослойных нейронных сетей, когда системе не сообщается информация о принадлежности образцов к тому или иному классу. Нейронной сети предъявляются только входные сигналы, а выходы сети формируются самостоятельно с учётом только входных и производных от них сигналов. Несмотря на многочисленные прикладные достижения, обучение «с учителем» критиковалось за биологическую неправдоподобность. Трудно вообразить обучающий механизм в естественном человеческом интеллекте, который сравнивал бы желаемые и действительные значения выходов, выполняя коррекцию с помощью обратной связи. Если допустить подобный механизм в человеческом мозге, то откуда тогда возникают желаемые выходы? Обучение «без учителя» является более правдоподобной моделью обучения в биологической системе. Она не нуждается в целевом векторе для выходов и, следовательно, не требует сравнения с предопределёнными идеальными ответами. Обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса нейронной сети так, чтобы получались согласованные выходные векторы, т. е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход вектора из данного класса даст определённый выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Это не является серьёзной проблемой. Обычно не сложно идентифицировать связь между входом и выходом, установленную сетью.
Кластеризации посвящено множество научных работ. Основная задача кластеризации заключается в обработке множества векторов в многомерном пространстве признаков с выделением компактных подмножеств (подмножеств, близко расположенных друг к другу), их количества и свойств. Наиболее распространённым методом кластеризации является метод «$K$ -means», практически не связанный с методами обратного распространения и не обобщаемый на архитектуры типа многослойных нейронных сетей.
Введение понятия квалификации «учителя» и единого подхода к обучению и самообучению в 1960-е годы позволило фактически создать основу для реализации режима кластеризации в многослойных нейронных сетях широкого класса структур.
Существующие разработки в области систем распознавания образов на базе многослойных нейронных сетей в основном относятся к стационарным образам, т.е. к случайным входным сигналам, имеющим сложные неизвестные, но стационарные во времени функции распределения. В некоторых работах была сделана попытка распространить предлагаемую методику настройки многослойных нейронных сетей на нестационарные образы, когда предполагаемая неизвестная функции распределения входного сигнала зависит от времени или входной случайный сигнал является суперпозицией регулярной составляющей и случайной составляющей с неизвестной сложной функцией распределения, не зависящей от времени.
Вероятностная модель мира, взятая за основу при построении алгоритмов адаптации в многослойных нейронных сетях, позволила формировать критерий первичной оптимизации в рассматриваемых системах в виде требований минимума средней функции риска и его модификаций: максимум апостериорной вероятности (условная вероятность случайного события при условии того, что известны апостериорные, т. е. основанные на опыте, данные); минимум средней функции риска; минимум средней функции риска при условии равенства условных функций риска для различных классов; минимум средней функции риска при условии заданного значения условной функции риска для одного из классов; другие критерии первичной оптимизации, вытекающие из требований конкретной практической задачи. В работах российских учёных были представлены модификации алгоритмов настройки многослойных нейронных сетей для указанных выше критериев первичной оптимизации. Отметим, что в подавляющем большинстве работ в области теории нейронных сетей и в алгоритмах обратного распространения рассматривается простейший критерий – минимум среднеквадратической ошибки, без каких бы то ни было ограничений на условные функции риска.
В режиме самообучения (кластеризации) предпосылкой формирования критерия и функционала первичной оптимизации нейронных сетей служит представление функции распределения входного сигнала в виде многомодальной функции в многомерном пространстве признаков, где каждой моде с некоторой вероятностью соответствует класс. В качестве критериев первичной оптимизации в режиме самообучения использовались модификации средней функции риска.
Представленные модификации критериев первичной оптимизации были обобщены на случаи континуума классов и решений; континуума признаков входного пространства; континуума числа нейронов в слое; при произвольной квалификации учителя. Важным разделом формирования критерия и функционала первичной оптимизации в многослойных нейронных сетях при вероятностной модели мира является выбор матрицы потерь, которая в теории статистических решений определяет коэффициент потерь $L_{12}$ при ошибочном отнесении образов 1-го класса ко 2-му и коэффициент потерь $L_{21}$ при отнесении образов 2-го класса к 1-му. Как правило, по умолчанию матрица $L$ этих коэффициентов при синтезе алгоритмов настройки многослойных нейронных сетей, в том числе и при применении метода обратного распространения, принимается симметричной. На практике это не соответствует действительности. Характерным примером является система обнаружения мин с применением геолокатора. В этом случае потери при ошибочном отнесении камня к мине равнозначны некоторой небольшой потере времени пользователем геолокатора. Потери, связанные с ошибочным отнесением мины к классу камней, связаны с жизнью или значительной потерей здоровья пользователями геолокатора.
Данный этап синтеза ставит своей целью определение в общем виде статистических характеристик выходных и промежуточных сигналов нейронных сетей как многомерных, нелинейных объектов управления с целью дальнейшего формирования критерия и функционала вторичной оптимизации, т. е. функционала, реально оптимизируемого алгоритмом адаптации в конкретной нейронной сети. В подавляющем большинстве работ в качестве такого функционала принимается среднеквадратическая ошибка, что ухудшает качество решения или вообще не соответствует задаче оптимизации, поставленной критерием первичной оптимизации.
Разработаны методика и алгоритмы формирования функционала вторичной оптимизации, соответствующего заданному функционалу первичной оптимизации.
Алгоритм поиска экстремума применительно к конкретному функционалу вторичной оптимизации определяет алгоритм настройки коэффициентов многослойной нейронной сети. В начале 21 века наибольший практический интерес представляют подобные алгоритмы, реализованные в системе MatLab (сокращение от англ. «Matrix Laboratory» – пакет прикладных программ для решения задач технических вычислений и одноимённый язык программирования). Однако необходимо отметить частность алгоритмов адаптации в многослойных нейронных сетях, используемых в системах MatLab (Neural Network Toolbox – предоставляет функции и приложения для моделирования сложных нелинейных систем, которые описываются уравнениями; поддерживает обучение «с учителем» и «без учителя», прямым распространением, с радиальными базисными функциями и др.), и ориентацию этих алгоритмов не на специфику решаемых задач, а на воображаемую «геометрию» функционалов вторичной оптимизации. Эти алгоритмы не учитывают многих деталей специфики применения многослойных нейронных сетей при решении конкретных задач и, естественно, требуют коренной, если не принципиальной, переработки при переходе к мемристорным нейронным системам. Был проведён детальный сравнительный анализ метода обратного распространения и российских методов 1960–70-х годов. Основная особенность данных алгоритмов заключается в необходимости поиска локальных и глобального экстремумов многоэкстремального функционала в многомерном пространстве настраиваемых коэффициентов нейронной сети. Рост размеров нейронной сети ведёт к значительному росту числа настраиваемых коэффициентов, т. е. к росту размерности пространства поиска. Ещё в 1960-х годах в работах предлагались поисковые и аналитические процедуры расчёта градиента функционала вторичной оптимизации, а в классе аналитических процедур предлагалось и исследовалось применение для организации поиска не только первой, но и второй производной функционала вторичной оптимизации. Специфика многоэкстремальности функционала вторичной оптимизации привела в течение последующих десятилетий к появлению различных модификаций методов поиска (генетические алгоритмы и т. п.). Созданы алгоритмы поиска экстремумов функционалов вторичной оптимизации с ограничениями на величину, скорость и другие параметры весовых коэффициентов нейронных сетей. Именно эти методы должны быть основой работ по методам настройки нейронных сетей с применением мемристоров (весовых коэффициентов) с учётом таких специфических характеристик, как передаточные функции.
Выбор начальных условий итерационной процедуры поиска экстремумов функционалов вторичной оптимизации является важным этапом синтеза алгоритмов настройки многослойных нейронных сетей. Задача выбора начальных условий должна решаться специфически для каждой задачи, решаемой нейронной сетью, и быть неотъемлемой составляющей общей процедуры синтеза алгоритмов настройки многослойных нейронных сетей. Качественное решение этой задачи в значительной степени может сократить время настройки. Априорная сложность функционала вторичной оптимизации сделала необходимой введение процедуры выбора начальных условий в виде случайных значений коэффициентов с повторением этой процедуры и процедуры настройки коэффициентов. Эта процедура ещё в 1960-е годы казалась чрезвычайно избыточной с точки зрения времени, затрачиваемого на настройку коэффициентов. Однако, несмотря на это, она достаточно широко применяется и в настоящее время. Для отдельных задач тогда же была принята идея выбора начальных условий, специфических для данной решаемой задачи. Такая процедура была отработана для трёх задач: распознавание образов; кластеризация; нейроидентификация нелинейных динамических объектов.
Системный подход к построению алгоритмов поиска экстремума функционала вторичной оптимизации предполагает в качестве одного из режимов настройки перенастройку коэффициентов в каждом такте поступления образов на входе по текущему значению градиента функционала вторичной оптимизации. Разработаны алгоритмы настройки многослойных нейронных сетей с фильтрацией последовательности значений градиентов функционала вторичной оптимизации: фильтром нулевого порядка с памятью $m_n$ (для стационарных образов); фильтром $1, …, k$ -го порядка с памятью $m_n$ (для нестационарных образов) с различной гипотезой изменения во времени функций распределения для образов различных классов.
Главный вопрос – как выбрать структуру многослойной нейронной сети для решения выбранной конкретной задачи – до сих пор в значительной степени не решён. Можно предложить лишь разумный направленный перебор вариантов структур с оценкой их эффективности в процессе решения задачи. Однако оценка качества работы алгоритма настройки на конкретной выбранной структуре, конкретной задаче может быть недостаточно корректной. Так, для оценки качества работы линейных динамических систем управления применяются типовые входные сигналы (ступенчатый, квадратичный и т. д.), по реакции на которые оцениваются установившаяся ошибка (астатизм системы) и ошибки в переходных процессах.
Подобно этому, для многослойных нейронных сетей были разработаны типовые входные сигналы для проверки и сравнения работоспособности различных алгоритмов настройки. Естественно, что типовые входные сигналы для таких объектов, как многослойные нейронные сети, являются специфическими для каждой решаемой задачи. В первую очередь были разработаны типовые входные сигналы для следующих задач: распознавание образов; кластеризация; нейроуправление динамическими объектами.
Основным аксиоматическим принципом применения нейросетевых технологий вместо методов классической математической статистики является отказ от формализованного описания функций распределения вероятностей для входных сигналов и принятие концепции неизвестных, сложных функций распределения. Именно по этой причине были предложены следующие типовые входные сигналы.
Для задачи кластеризации была предложена выборка случайного сигнала с многомодальным распределением, реализуемая в $N$ -мерном пространстве признаков с модами функции распределения, центры которых в количестве $Z$ размещаются на гипербиссектрисе $N$ -мерного пространства признаков. Каждая мода реализует составляющую случайной выборки с нормальным распределением и среднеквадратичным отклонением $σ$ , равным для каждой из $Z$ мод. Предметом сравнения различных методов кластеризации будет динамика настройки и качество решения задачи в зависимости от $N$ , $Z$ и $σ$ , при достаточно большой случайной выборке $M$ . Этот подход можно считать одним из первых достаточно объективных подходов к сравнению алгоритмов кластеризации, в том числе основанных на многослойных нейронных сетях c соответствующим выбором структуры для достижения необходимого качества кластеризации. Для задач классификации входные сигналы для испытаний аналогичны сигналам для кластеризации с тем изменением, что выборка с многомодальным распределением делится надвое (в случае двух классов) или на $K$ (в случае $K$ классов) частей с перемежающимися модами функции распределения для отдельных классов.
Отказ в нейросетевых технологиях от априорной информации, от информации о функциях распределения входных сигналов приводит к необходимости реализации разумного перебора параметров структуры многослойных нейронных сетей для обеспечения необходимого качества решения задачи.
В 1960-е годы для весьма актуального в то время класса задач – распознавания образов – была предложена процедура настройки многослойных нейронных сетей, в которой структура априори не фиксируется, а является результатом настройки наряду со значениями настраиваемых коэффициентов. При этом в процессе настройки выбираются число слоёв и число нейронов в слоях. Процедура настройки коэффициентов многослойной нейронной сети с переменной структурой легко переносится с задачи распознавания двух классов образов на задачу распознавания $K$ классов образов. Причём здесь результатом настройки являются $K$ нейронных сетей, в каждой из которых первым классом является $k$ -й класс ($k = 1, \ldots, K$ ), а вторым все остальные. Подобная идея настройки многослойных нейронных сетей с переменной структурой применима и к решению задачи кластеризации. При этом в качестве первого класса образов принимается исходная анализируемая выборка, а в качестве второго класса – выборка с равномерным распределением в диапазоне изменения признаков. Реализуемая в процессе настройки многослойная нейронная сеть с переменной структурой качественно и количественно отражает сложность решения задачи. С этой точки зрения задача кластеризации как задача рождения новых знаний об изучаемом объекте заключается в выделении и анализе тех областей многомерного пространства признаков, в которых функция распределения вероятностей превышает уровень равномерного распределения в диапазоне изменения величин признаков.
В начале 21 века одной из основных концепций развития (обучения) многослойной нейронной сети является стремление к увеличению числа слоёв, а это предполагает обеспечение выбора структуры нейронной сети, адекватной решаемой задаче, разработку новых методов для формирования алгоритмов настройки коэффициентов. Достоинствами нейронных сетей являются: свойство т.н. постепенной деградации − при выходе из строя отдельных элементов качество работы системы падает постепенно (для сравнения, логические сети из элементов И, ИЛИ, НЕ выходят из строя при нарушении работы любого элемента сети); повышенная устойчивость к изменению параметров схем, их реализующих (например, весьма значительные изменения весов не приводят к ошибкам в реализации простой логической функции двух переменных) и др.
Широкое распространение нейросетевых алгоритмов в области сложных формализуемых, слабоформализуемых и неформализуемых задач привело к созданию нового направления в вычислительной математике – нейроматематики . Нейроматематика включает нейросетевые алгоритмы решения следующих задач: распознавание образов; оптимизация и экстраполяция функций; теории графов; криптографические задачи; решение вещественных и булевских систем линейных и нелинейных уравнений, обыкновенных одномерных и многомерных дифференциальных уравнений, дифференциальных уравнений в частных производных и др. На основе теории нейронных сетей создан новый раздел современной теории управления сложными нелинейными и многомерными, многосвязными динамическими системами – нейроуправление , включающий методы нейросетевой идентификации сложных динамических объектов; построение нейрорегуляторов в контурах управления сложными динамическими объектами и др.