Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры нейронной сети.
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как обучение нейронной сети.
Каждая итерация обучающего процесса состоит из следующих шагов
Последовательный график ниже иллюстрирует процесс:

Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется градиентным спуском .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
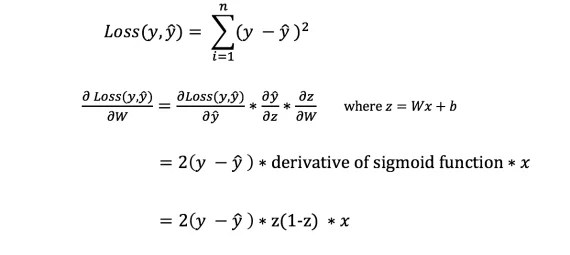
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
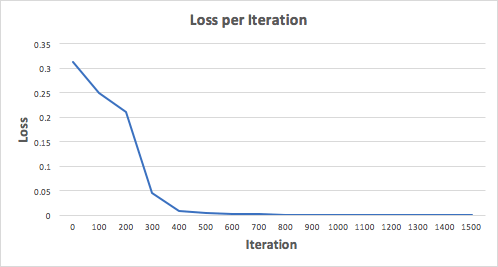
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.
Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
Искусственная нейронная сеть — совокупность нейронов, взаимодействующих друг с другом. Они способны принимать, обрабатывать и создавать данные. Это настолько же сложно представить, как и работу человеческого мозга. Нейронная сеть в нашем мозгу работает для того, чтобы вы сейчас могли это прочитать: наши нейроны распознают буквы и складывают их в слова.
Искусственная нейронная сеть - это подобие мозга. Изначально она программировалась с целью упростить некоторые сложные вычислительные процессы. Сегодня у нейросетей намного больше возможностей. Часть из них находится у вас в смартфоне. Ещё часть уже записала себе в базу, что вы открыли эту статью. Как всё это происходит и для чего, читайте далее.
Людям очень хотелось понять, откуда у человека разум и как работает мозг. В середине прошлого века канадский нейропсихолог Дональд Хебб это понял. Хебб изучил взаимодействие нейронов друг с другом, исследовал, по какому принципу они объединяются в группы (по-научному - ансамбли) и предложил первый в науке алгоритм обучения нейронных сетей.
Спустя несколько лет группа американских учёных смоделировала искусственную нейросеть, которая могла отличать фигуры квадратов от остальных фигур.
Исследователи выяснили, нейронная сеть - это совокупность слоёв нейронов, каждый из которых отвечает за распознавание конкретного критерия: формы, цвета, размера, текстуры, звука, громкости и т. д. Год от года в результате миллионов экспериментов и тонн вычислений к простейшей сети добавлялись новые и новые слои нейронов. Они работают по очереди. Например, первый определяет, квадрат или не квадрат, второй понимает, квадрат красный или нет, третий вычисляет размер квадрата и так далее. Не квадраты, не красные и неподходящего размера фигуры попадают в новые группы нейронов и исследуются ими.
Учёные развили нейронные сети так, что те научились различать сложные изображения, видео, тексты и речь. Типов нейронных сетей сегодня очень много. Они классифицируются в зависимости от архитектуры - наборов параметров данных и веса этих параметров, некой приоритетности. Ниже некоторые из них.
Нейроны делятся на группы, каждая группа вычисляет заданную ей характеристику. В 1993 году французский учёный Ян Лекун показал миру LeNet 1 - первую свёрточную нейронную сеть, которая быстро и точно могла распознавать цифры, написанные на бумаге от руки. Смотрите сами:
Сегодня свёрточные нейронные сети используются в основном с мультимедиными целями: они работают с графикой, аудио и видео.
Нейроны последовательно запоминают информацию и строят дальнейшие действия на основе этих данных. В 1997 году немецкие учёные модифицировали простейшие рекуррентные сети до сетей с долгой краткосрочной памятью. На их основе затем были разработаны сети с управляемыми рекуррентными нейронами.
Сегодня с помощью таких сетей пишутся и переводятся тексты, программируются боты, которые ведут осмысленные диалоги с человеком, создаются коды страниц и программ.
Использование такого рода нейросетей - это возможность анализировать и генерировать данные, составлять базы и даже делать прогнозы.
В 2015 году компания SwiftKey выпустила первую в мире клавиатуру, работающую на рекуррентной нейросети с управляемыми нейронами. Тогда система выдавала подсказки в процессе набранного текста на основе последних введённых слов. В прошлом году разработчики обучили нейросеть изучать контекст набираемого текста, и подсказки стали осмысленными и полезными:

Такие нейронные сети способны понимать, что находится на изображении, и описывать это. И наоборот: рисовать изображения по описанию. Ярчайший пример продемонстрировал Кайл Макдональд, взяв нейронную сеть на прогулку по Амстердаму. Сеть мгновенно определяла, что находится перед ней. И практически всегда точно:

1. Skype внедрил возможность синхронного перевода уже для 10 языков. Среди которых, на минуточку, есть русский и японский - одни из самых сложных в мире. Конечно, качество перевода требует серьёзной доработки, но сам факт того, что уже сейчас вы можете общаться с коллегами из Японии по-русски и быть уверенными, что вас поймут, вдохновляет.
2. Яндекс на базе нейронных сетей создал два поисковых алгоритма: «Палех» и «Королёв». Первый помогал найти максимально релевантные сайты для низкочастотных запросов. «Палех» изучал заголовки страниц и сопоставлял их смысл со смыслом запросов. На основе «Палеха» появился «Королёв». Этот алгоритм оценивает не только заголовок, но и весь текстовый контент страницы. Поиск становится всё точнее, а владельцы сайтов разумнее начинают подходить к наполнению страниц.
3. Коллеги сеошников из Яндекса создали музыкальную нейросеть: она сочиняет стихи и пишет музыку. Нейрогруппа символично называется Neurona, и у неё уже есть первый альбом:

4. У Google Inbox с помощью нейросетей осуществляется ответ на сообщение. Развитие технологий идет полный ходом, и сегодня сеть уже изучает переписку и генерирует возможные варианты ответа. Можно не тратить время на печать и не бояться забыть какую-нибудь важную договорённость.

5. YouTube использует нейронные сети для ранжирования роликов, причём сразу по двум принципам: одна нейронная сеть изучает ролики и реакции аудитории на них, другая проводит исследование пользователей и их предпочтений. Именно поэтому рекомендации YouTube всегда в тему.
6. Facebook активно работает над DeepText AI - программой для коммуникаций, которая понимает жаргон и чистит чатики от обсценной лексики.
7. Приложения вроде Prisma и Fabby, созданные на нейросетях, создают изображения и видео:

Colorize восстанавливает цвета на чёрно-белых фото (удивите бабушку!).

MakeUp Plus подбирает для девушек идеальную помаду из реального ассортимента реальных брендов: Bobbi Brown, Clinique, Lancome и YSL уже в деле.

8.
Apple и Microsoft постоянно апгрейдят свои нейронные Siri и Contana. Пока они только исполняют наши приказы, но уже в ближайшем будущем начнут проявлять инициативу: давать рекомендации и предугадывать наши желания.
Самообучающиеся нейросети могут заменить людей: начнут с копирайтеров и корректоров. Уже сейчас роботы создают тексты со смыслом и без ошибок. И делают это значительно быстрее людей. Продолжат с сотрудниками кол-центров, техподдержки, модераторами и администраторами пабликов в соцсетях. Нейронные сети уже умеют учить скрипт и воспроизводить его голосом. А что в других сферах?
Нейросеть внедрят в спецтехнику. Комбайны будут автопилотироваться, сканировать растения и изучать почву, передавая данные нейросети. Она будет решать - полить, удобрить или опрыскать от вредителей. Вместо пары десятков рабочих понадобятся от силы два специалиста: контролирующий и технический.
В Microsoft сейчас активно работают над созданием лекарства от рака. Учёные занимаются биопрограммированием - пытаются оцифрить процесс возникновения и развития опухолей. Когда всё получится, программисты смогут найти способ заблокировать такой процесс, по аналогии будет создано лекарство.
Маркетинг максимально персонализируется. Уже сейчас нейросети за секунды могут определить, какому пользователю, какой контент и по какой цене показать. В дальнейшем участие маркетолога в процессе сведётся к минимуму: нейросети будут предсказывать запросы на основе данных о поведении пользователя, сканировать рынок и выдавать наиболее подходящие предложения к тому моменту, как только человек задумается о покупке.
Ecommerce будет внедрён повсеместно. Уже не потребуется переходить в интернет-магазин по ссылке: вы сможете купить всё там, где видите, в один клик. Например, читаете вы эту статью через несколько лет. Очень вам нравится помада на скрине из приложения MakeUp Plus (см. выше). Вы кликаете на неё и попадаете сразу в корзину. Или смотрите видео про последнюю модель Hololens (очки смешанной реальности) и тут же оформляете заказ прямо из YouTube.
Едва ли не в каждой области будут цениться специалисты со знанием или хотя бы пониманием устройства нейросетей, машинного обучения и систем искусственного интеллекта. Мы будем существовать с роботами бок о бок. И чем больше мы о них знаем, тем спокойнее нам будет жить.
P. S.
Зинаида Фолс - нейронная сеть Яндекса, пишущая стихи. Оцените произведение, которое машина написала, обучившись на Маяковском (орфография и пунктуация сохранены):
« Это »
это
всего навсего
что-то
в будущем
и мощь
у того человека
есть на свете все или нет
это кровьа вокруг
по рукам
жиреет
слава у
земли
с треском в клюве
Впечатляет, правда?
Что мы будем делать? Мы попробуем создать простую и совсем маленькую нейронную сеть , которую мы объясним
и научим
что-нибудь различать. При этом не будем вдаваться в историю и математические дебри (такую информацию найти очень легко) — вместо этого постараемся объяснить задачу (не факт, что удастся) вам и самим себе рисунками и кодом.
Многие из терминов в нейронных сетях связаны с биологией, поэтому давайте начнем с самого начала:
Мозг — штука сложная, но и его можно разделить на несколько основных частей и операций:
Возбудитель может быть и внутренним (например, образ или идея):
А теперь взглянем на основные и упрощенные части мозга :
Мозг вообще похож на кабельную сеть.
Нейрон — основная единица исчислений в мозге, он получает и обрабатывает химические сигналы других нейронов, и, в зависимости от ряда факторов, либо не делает ничего, либо генерирует электрический импульс, или Потенциал Действия, который затем через синапсы подает сигналы соседним связанным нейронам:
Сны, воспоминания, саморегулируемые движения, рефлексы да и вообще все, что вы думаете или делаете — все происходит благодаря этому процессу: миллионы, или даже миллиарды нейронов работают на разных уровнях и создают связи, которые создают различные параллельные подсистемы и представляют собой биологическую нейронную сеть .
Разумеется, это всё упрощения и обобщения, но благодаря им мы можем описать простую
нейронную сеть:
И описать её формализовано с помощью графа:
Тут требуются некоторые пояснения. Кружки — это нейроны, а линии — это связи между ними, и, чтобы не усложнять на этом этапе, взаимосвязи представляют собой прямое передвижение информации слева направо . Первый нейрон в данный момент активен и выделен серым. Также мы присвоили ему число (1 — если он работает, 0 — если нет). Числа между нейронами показывают вес связи.
Графы выше показывают момент времени сети, для более точного отображения, нужно разделить его на временные отрезки:
Для создания своей нейронной сети нужно понимать, как веса влияют на нейроны и как нейроны обучаются. В качестве примера возьмем кролика (тестового кролика) и поставим его в условия классического эксперимента.
Когда на них направляют безопасную струю воздуха, кролики, как и люди, моргают:
Эту модель поведения можно нарисовать графами:
Как и в предыдущей схеме, эти графы показывают только тот момент, когда кролик чувствует дуновение, и мы таким образом кодируем дуновение как логическое значение. Помимо этого мы вычисляем, срабатывает ли второй нейрон, основываясь на значении веса. Если он равен 1, то сенсорный нейрон срабатывает, мы моргаем; если вес меньше 1, мы не моргаем: у второго нейрона предел — 1.
Введем еще один элемент — безопасный звуковой сигнал:
Мы можем смоделировать заинтересованность кролика так:
Основное отличие в том, что сейчас вес равен нулю
, поэтому моргающего кролика мы не получили, ну, пока, по крайней мере. Теперь научим кролика моргать по команде, смешивая
раздражители (звуковой сигнал и дуновение):
Важно, что эти события происходят в разные временные эпохи , в графах это будет выглядеть так:
Сам по себе звук ничего не делает, но воздушный поток по-прежнему заставляет кролика моргать, и мы показываем это через веса, умноженные на раздражители (красным). Обучение сложному поведению можно упрощённо выразить как постепенное изменение веса между связанными нейронами с течением времени.
Чтобы обучить кролика, повторим действия:
Для первых трех попыток схемы будут выглядеть так:
Обратите внимание, что вес для звукового раздражителя растет после каждого повтора (выделено красным), это значение сейчас произвольное — мы выбрали 0.30, но число может быть каким угодно, даже отрицательным. После третьего повтора вы не заметите изменения в поведении кролика, но после четвертого повтора произойдет нечто удивительное — поведение изменится.
Мы убрали воздействие воздухом, но кролик все еще моргает, услышав звуковой сигнал! Объяснить это поведение может наша последняя схемка:
Мы обучили кролика реагировать на звук морганием.
В условиях реального эксперимента такого рода может потребоваться более 60 повторений для достижения результата.
Теперь мы оставим биологический мир мозга и кроликов и попробуем адаптировать всё, что
узнали, для создания искусственной нейросети. Для начала попробуем сделать простую задачу.
Допустим, у нас есть машина с четырьмя кнопками, которая выдает еду при нажатии правильной
кнопки (ну, или энергию, если вы робот). Задача — узнать, какая кнопка выдает вознаграждение:
Мы можем изобразить (схематично), что делает кнопка при нажатии следующим образом:
Такую задачу лучше решать целиком, поэтому давайте посмотрим на все возможные результаты, включая правильный:
Нажмите на 3-ю кнопку, чтобы получить свой ужин.
Чтобы воспроизвести нейронную сеть в коде, нам для начала нужно сделать модель или график, с которым можно сопоставить сеть. Вот один подходящий под задачу график, к тому же он хорошо отображает свой биологический аналог:
Эта нейронная сеть просто получает входящую информацию — в данном случае это будет восприятие того, какую кнопку нажали. Далее сеть заменяет входящую информацию на веса и делает вывод на основе добавления слоя. Звучит немного запутанно, но давайте посмотрим, как в нашей модели представлена кнопка:
Обратите внимание, что все веса равны 0, поэтому нейронная сеть, как младенец, совершенно пуста, но полностью взаимосвязана.
Таким образом мы сопоставляем внешнее событие с входным слоем нейронной сети и вычисляем значение на ее выходе. Оно может совпадать или не совпадать с реальностью, но это мы пока проигнорируем и начнем описывать задачу понятным компьютеру способом. Начнем с ввода весов (будем использовать JavaScript):
Var inputs = ; var weights = ; // Для удобства эти векторы можно назвать
Следующий шаг — создание функции, которая собирает входные значения и веса и рассчитывает значение на выходе:
Function evaluateNeuralNetwork(inputVector, weightVector){ var result = 0; inputVector.forEach(function(inputValue, weightIndex) { layerValue = inputValue*weightVector; result += layerValue; }); return (result.toFixed(2)); } // Может казаться комплексной, но все, что она делает — это сопоставляет пары вес/ввод и добавляет результат
Как и ожидалось, если мы запустим этот код, то получим такой же результат, как в нашей модели или графике…
EvaluateNeuralNetwork(inputs, weights); // 0.00
Живой пример: Neural Net 001 . Следующим шагом в усовершенствовании нашей нейросети будет способ проверки её собственных выходных или результирующих значений сопоставимо реальной ситуации, давайте сначала закодируем эту конкретную реальность в переменную:
Чтобы обнаружить несоответствия (и сколько их), мы добавим функцию ошибки:
Error = Reality - Neural Net Output
С ней мы можем оценивать работу нашей нейронной сети:
Но что более важно — как насчет ситуаций, когда реальность дает положительный результат?
Теперь мы знаем, что наша модель нейронной сети не работает (и знаем, насколько), здорово! А здорово это потому, что теперь мы можем использовать функцию ошибки для управления нашим обучением. Но всё это обретет смысл в том случае, если мы переопределим функцию ошибок следующим образом:
Error = Desired Output - Neural Net Output
Неуловимое, но такое важное расхождение, молчаливо показывающее, что мы будем
использовать ранее полученные результаты для сопоставления с будущими действиями
(и для обучения, как мы потом увидим). Это существует и в реальной жизни, полной
повторяющихся паттернов, поэтому оно может стать эволюционной стратегией (ну, в
большинстве случаев).
Var input = ; var weights = ; var desiredResult = 1;
И новую функцию:
Function evaluateNeuralNetError(desired,actual) { return (desired — actual); } // After evaluating both the Network and the Error we would get: // "Neural Net output: 0.00 Error: 1"
Живой пример: Neural Net 002 . Подведем промежуточный итог . Мы начали с задачи, сделали её простую модель в виде биологической нейронной сети и получили способ измерения её производительности по сравнению с реальностью или желаемым результатом. Теперь нам нужно найти способ исправления несоответствия — процесс, который как и для компьютеров, так и для людей можно рассматривать как обучение.
Как обучать нейронную сеть?
Основа обучения как биологической, так и искусственной нейронной сети — это повторение
и алгоритмы обучения
, поэтому мы будем работать с ними по отдельности. Начнем с
обучающих алгоритмов.
В природе под алгоритмами обучения понимаются изменения физических или химических
характеристик нейронов после проведения экспериментов:
Драматическая иллюстрация того, как два нейрона меняются по прошествии времени в коде и нашей модели «алгоритм обучения» означает, что мы просто будем что-то менять в течение какого-то времени, чтобы облегчить свою жизнь. Поэтому давайте добавим переменную для обозначения степени облегчения жизни:
Var learningRate = 0.20; // Чем больше значение, тем быстрее будет процесс обучения:)
И что это изменит?
Это изменит веса (прям как у кролика!), особенно вес вывода, который мы хотим получить:
Как кодировать такой алгоритм — ваш выбор, я для простоты добавляю коэффициент обучения к весу, вот он в виде функции:
Function learn(inputVector, weightVector) { weightVector.forEach(function(weight, index, weights) { if (inputVector > 0) { weights = weight + learningRate; } }); }
При использовании эта обучающая функция просто добавит наш коэффициент обучения к вектору веса активного нейрона , до и после круга обучения (или повтора) результаты будут такими:
// Original weight vector: // Neural Net output: 0.00 Error: 1 learn(input, weights); // New Weight vector: // Neural Net output: 0.20 Error: 0.8 // Если это не очевидно, вывод нейронной сети близок к 1 (выдача курицы) — то, чего мы и хотели, поэтому можно сделать вывод, что мы движемся в правильном направлении
Живой пример: Neural Net 003 . Окей, теперь, когда мы движемся в верном направлении, последней деталью этой головоломки будет внедрение повторов .
Это не так уж и сложно, в природе мы просто делаем одно и то же снова и снова, а в коде мы просто указываем количество повторов:
Var trials = 6;
И внедрение в нашу обучающую нейросеть функции количества повторов будет выглядеть так:
Function train(trials) { for (i = 0; i < trials; i++) { neuralNetResult = evaluateNeuralNetwork(input, weights); learn(input, weights); } }
Ну и наш окончательный отчет:
Neural Net output: 0.00 Error: 1.00 Weight Vector: Neural Net output: 0.20 Error: 0.80 Weight Vector: Neural Net output: 0.40 Error: 0.60 Weight Vector: Neural Net output: 0.60 Error: 0.40 Weight Vector: Neural Net output: 0.80 Error: 0.20 Weight Vector: Neural Net output: 1.00 Error: 0.00 Weight Vector: // Chicken Dinner !
Живой пример: Neural Net 004 . Теперь у нас есть вектор веса, который даст только один результат (курицу на ужин), если входной вектор соответствует реальности (нажатие на третью кнопку). Так что же такое классное мы только что сделали?
В этом конкретном случае наша нейронная сеть (после обучения) может распознавать входные данные и говорить, что приведет к желаемому результату (нам всё равно нужно будет программировать конкретные ситуации):
Кроме того, это масштабируемая модель, игрушка и инструмент для нашего с вами обучения. Мы смогли узнать что-то новое о машинном обучении , нейронных сетях и искусственном интеллекте . Предостережение пользователям:
Заметки и список литературы для дальнейшего чтения
Я пытался избежать математики и строгих терминов, но если вам интересно, то мы построили перцептрон , который определяется как алгоритм контролируемого обучения (обучение с учителем) двойных классификаторов — тяжелая штука. Биологическое строение мозга — тема не простая, отчасти из-за неточности, отчасти из-за его сложности. Лучше начинать с Neuroscience (Purves) и Cognitive Neuroscience (Gazzaniga). Я изменил и адаптировал пример с кроликом из Gateway to Memory (Gluck), которая также является прекрасным проводником в мир графов. Еще один шикарный ресурс An Introduction to Neural Networks (Gurney), подойдет для всех ваших нужд, связанных с ИИ.
А теперь на Python! Спасибо Илье Андшмидту за предоставленную версию на Python:
Inputs = weights = desired_result = 1 learning_rate = 0.2 trials = 6 def evaluate_neural_network(input_array, weight_array): result = 0 for i in range(len(input_array)): layer_value = input_array[i] * weight_array[i] result += layer_value print("evaluate_neural_network: " + str(result)) print("weights: " + str(weights)) return result def evaluate_error(desired, actual): error = desired - actual print("evaluate_error: " + str(error)) return error def learn(input_array, weight_array): print("learning...") for i in range(len(input_array)): if input_array[i] > 0: weight_array[i] += learning_rate def train(trials): for i in range(trials): neural_net_result = evaluate_neural_network(inputs, weights) learn(inputs, weights) train(trials)
А теперь на GO! За эту версию благодарю Кирана Мэхера.
Package main import ("fmt" "math") func main() { fmt.Println("Creating inputs and weights ...") inputs:= float64{0.00, 0.00, 1.00, 0.00} weights:= float64{0.00, 0.00, 0.00, 0.00} desired:= 1.00 learningRate:= 0.20 trials:= 6 train(trials, inputs, weights, desired, learningRate) } func train(trials int, inputs float64, weights float64, desired float64, learningRate float64) { for i:= 1; i < trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print(" Error: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print(" ") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue > 0.00 { weightVector = weightVector + learningRate } } return weightVector } func evaluate(inputVector float64, weightVector float64) float64 { result:= 0.00 for index, inputValue:= range inputVector { layerValue:= inputValue * weightVector result = result + layerValue } return result } func evaluateError(desired float64, actual float64) float64 { return desired - actual }
Про нейронные сети хорошо и подробно написано здесь. Попытаемся разобраться как программировать нейронные сети, и как это работает . Одна из задач решаемых нейронными сетями, задача классификации. Программа демонстрирует работу нейронной сети классифицирующей цвет.
В компьютере принята трехкомпонентная модель представления цвета RGB, на каждый из компонентов отводится один байт. полный цвет представлен 24 битами, что дает 16 миллионов оттенков. Человек же может отнести любой из этих оттенков к одному из имеющих название цветов. Итак задача:
Дано InColor — цвет RGB (24 бит)
классифицировать цвет, т.е. отнести его к одному из цветов заданных множеством М={ Черный, Красный, Зеленый, Желтый, Синий, Фиолетовый, Голубой, Белый }.
OutColor — цвет из множества М
Решение номер 1. (цифровое)
Создаем массив размером 16777216 элементов
Решение номер 2. (аналоговое)
напишем функцию, типа
|
int8 GetColor(DWORD Color) |
Это будет работать если задачу можно описать простыми уравнениями, а вот если функция настолько сложна что описанию. не поддается, здесь то на помощь приходят нейронные сети.
Решение номер 3. (нейронная сеть)
Простейшая нейронная сеть. Однослойный перцептрон.
Все нейронное заключено в класс CNeuroNet
Каждый нейрон имеет 3 входа, куда подаются интенсивности компонент цвета. (R,G,B) в диапазоне (0 — 1). Всего нейронов 8, по количеству цветов в выходном множестве. В результате работы сети на выходе каждого нейрона формируется сигнал в диапазоне (0 — 1), который означает вероятность того что на входе этот цвет. Выбираем максимальный и получаем ответ.
Нейроны имеют сигмоидную функцию активации ActiveSigm(). Функция ActiveSigmPro(), производная от сигмоидной функции активации используется для обучения нейронной сетиметодом обратного распространения.
В первой строчке выведены интенсивности цветов. ниже таблица весовых коэффициентов (4 шт.). В последнем столбце значение на выходе нейронов. Меняем цвет, выбираем из списка правильный ответ, кнопкой Teach вызываем функцию обучения. AutoTeach вызывает процедуру автоматического обучения, 1000 раз, случайный цвет определяется по формуле из решения номер 2, и вызывается функция обучения.
скачать исходный код и программу нейронной сети

Для простых нейроархитектур (структур), методов и задач можно использовать любой язык (даже Бэйсик), но для сложных проектов наиболее пригодными оказываются языки объектно-ориентированного программирования (такие, как С++). Я применяю именно С++, при необходимости (в наиболее времязатратных местах программы) переписывая отдельные функции (требующие ускорения вычислений) на инлайн-ассемблере.
Покажем пользу объектно-ориентированного подхода к программированию нейросеток. У нейросети может быть множество вариантов нейронов и/или слоёв (см. заметку про современные возможности собрать свёрточную нейросеть из большого числа разнотипных слоёв и нейронов). Некоторую общую функциональность нейронов или слоёв можно вынести в абстрактный класс-предок, порождая (наследуя) от него классы для тех или иных видов нейронов/слоёв (эти классы-потомки будут описывать-реализовывать уже уникальные для конкретного вида нейрона или слоя особенности и поведение). Таким образом обеспечиваются ликвидация многократного дублирования общих (одинаковых) вещей в тексте программы и возможность написать более гибкий и независимый от конкретных типов нейронов/слоёв управляющий код программы при использовании принципов полиморфизма.
В качестве примера рассмотрим номенклатуру классов для описания слоёв нейросети в одной из разработанных мной программ. Имеется 3 основных иерархии − одна для классов-описателей структуры слоя (цепочка наследования из трёх классов), вторая − для нелинейных функций нейронов (базовый класс и десять наследников от него), третья − для самих слоёв (цепочка из 5 базовых-промежуточных классов и 12 реальных классов, отпочковавшихся от этой цепочки на разных её уровнях).
в тексте программы для описания поведения слоёв сети использован (реализован) 31 класс, но при этом всего 12 из них реализуют реальные слои, а остальные классы:
Функционирование созданной нейронной сети запрограммировано через обращения к методам и свойствам абстрактных классов, независимо от того, какой конкретно класс-потомок реализует тот или иной слой нейросети.
Т.е. управляющая логика здесь отделена от конкретного содержания и привязана только к общим, инвариантным основам. О конкретных же классах необходимо знать только коду «конструктора» нейросети − работающего только в момент создания новой сети исходя из заданных в интерфейсе настроек или при загрузке ранее сохранённой сети из файла. Добавление новых типов слоёв нейронов в программу не приведёт к переделке алгоритмов (логики) работы и обучения сети − а потребует только небольшого дополнения кода механизмов создания (или чтения из файла) нейросети.
Абстракций (классов) для отдельных нейронов нет — только для слоёв. Если нужно поставить на некотором (а именно — на выходном) слое единственный нейрон — то просто экземпляру класса нужного нейронного слоя при создании передаётся счётчик числа нейронов, равный единице.
Таким образом, объектно-ориентированные проектирование и программирование обеспечивают бОльшую гибкость для реализации принципа «разделяй и властвуй» по сравнению со структурным программированием, через:
Для современных задач разработки гибких и мощных инструментов нейромоделирования всё это оказывается очень полезным.
Также см. пост про проекты специальных языков описания ИНС.
нейронные сети,
методы анализа данных:
от исследований до разработок и внедрений
Главная
Услуги
Нейронные сети
базовые идеи
возможности
преимущества
области применения
как использовать
Точность решения
НС и ИИ
Программы
Статьи
Блог
Об авторе / контакты
Тонкая настройка Вселенной — это уникальное сочетание многочисленных свойств Вселенной такое, что только оно и способно обеспечить существование наблюдаемой Вселенной. Даже минимальные отклонения состава или значений этих свойств несовместимы с фактом существования Вселенной.
Обычно понятие тонкой настройки Вселенной рассматривается в слабой формулировке: принимаются во внимание значения всего нескольких мировых констант, и делается вывод только о невозможности существования человечества при их отклонениях. Такой ограниченный подход стимулирует религиозно окрашенные попытки объяснения этого явления, например, антропный принцип , декларирующий богоданную целесообразность Вселенной, заключенную в существовании человека.
Тонкая настройка Вселенной — это самая впечатляющая из аперцепций современной космологии: никакая другая не сравнится с ней по силе и убедительности свидетельства о Большом тупике, о том, что Вселенная устроена категорически не так, как её представляет современная наука, и в рамках этого представления исследует. Не несколько констант, а вообще непредставимо огромный корпус разнообразных фактов, имей любой из них даже небольшое отличие от наблюдаемого, сделал бы невозможным существование жизни и Вселенной. Значения свойств элементарных частиц (массы, заряды, периоды полураспада…), свойства фундаментальных взаимодействий, свойства веществ (да хотя бы воды), — всё это и многое-многое другое тщательно выбрано именно таким, чтобы Вселенная существовала. Любой из миллионов этих фактов, будь он другим, привёл бы её к несуществованию. Или, как минимум (в слабой формулировке) — к невозможности жизни в ней.
Осознание этого полностью разрушает привычную "научную картину мира" эпохи Большого тупика. Но, как уже сказано, здесь имеет место аперцепция: люди отказываются осознавать это.
ИТВ устанавливает, что Вселенная состоит только из информации. Наблюдатель наблюдает наблюдаемое, получая информацию — и это всё, что составляет Вселенную. Информация, будучи всего лишь описанием чего-либо, могла бы быть любой возможной, если бы она получалась сама по себе. Однако информация сама по себе ничем не является и ничего описывать не может, для этого всегда нужны некоторые условия, и они ограничивают содержание информации.
Таким образом, Вселенная — это совокупность обусловленных выборов конкретной наблюдаемой информации из широкой гаммы в принципе возможной. Существование Вселенной является финальным критерием всех этих выборов: они таковы постольку, поскольку Вселенная существует, будь они другими — Вселенная не существовала бы.
Это и есть тонкая настройка Вселенной: значения мировых констант и вообще все свойства Вселенной определились фактом существования Вселенной, никто их специально не подбирал, ни из какой единой константы они не выводятся, никакой возможности установить их иной состав и иные значения не существует.
В данной статье предлагаю разобрать дейтсвие нейронных сетей и накидать один из простейших вариантов нейронной сети, обучающейся при помощи учителя.
Пару слов, необходимо уделить устройству этой самой «великой» и «ужасной» нейронной сети. Долгое количество времени люди ходили взад и вперед и размышляли над вопросом: (в чем смысл жизни?)
Как можно распознавать образы?
Ответов было огромное множество. Тут и различные эвристики, и сравнения по шаблонам и многое-многое. Одним из ответов была нейронная сеть. [К слову сказать нейронная сеть может не только распознавать образы]
Итак. Структура нейронной сети. Представьте себе такую картину: паук сплел сеть и сеть словила муху. То место на которое попала муха и есть нейрон, который был «максимально» близок к цели. Нейронная сеть состоит из нейронов, которые «описывают»
шансы того или иного события. Описание «вероятности» события (каждого нейрона) может храниться (к примеру) в отдельном файле.
Теперь переходим к главной теме разговора этого вечера.
Как устроена нейронная сеть.
Как происходит ее обучение и распознание.
Пример структуры нейронной сети отчеливо виден на этой картинке:
На вход поступает множество входных сигналов X. Которые умножаются на множество весов W (Xi * Wi). В нейроне производится подсчет суммы произведений и на выход отправляется некоторое число.
После подсчета значений у всех нейронов, производится поиск наибольшего значения. Это наибольшее значение и считается корректным ответом на вопрос. Программой выдается образ, который описывается найденным нейроном.
В режиме обучения пользователь имеет возможность подправить результат (основываясь на своем опыте) и тогда программа произведет пересчет весов нейронов.
Формула перерасчета примерно следующая: W[i] = W[i] + Speed*Delta*X[i] — здесь
W[i] — вес i-го элемента,
Speed — скорость обучения,
Delta — знак (-1 или 1),
X[i] — значение i-го входящего сигнала (во многих случаях 0 или 1)
Зачем используется delta?
Разберем такой случай.
На вход программе подается картинка с цифрой 6.
Нейронная сеть распознала цифру 8. Пользователь правит цифру на 6. Что происходит далее в программе?
Программа пересчитывает данные для двух нейронов, описывающих число 6 и число 8, причем для нейрона, описывающего число 6 delta будет равна 1, а для 8 = -1
Как задается параметр скорости?
Данный параметр, чем меньше тем, дольше и точнее(качетственнее) будет происходить обучение сети, и чем больше, тем быстрее и «поверхностней» будет происходить обучение сети.
Параметр Speed может задаваться как вручную, пользователем, так и в ходе выполнения программы(к примеру const)
Как видно, весы символов также должны быть определены. А чем они определяются изначально? на самом деле тут также все просто. Определяются они совершенно случайно, это позволяет избежать «предвзятости» нейронной сети. Обычно, интервал случайных значений небольшой -0.4…0.4 или -0.3..0.2 и т.п.
Теперь переходим к самой интересной части. Как это закодировать!
Создадим два класса — класс Нейрон и класс Сеть (Neuron и Net соответственно)
Опишем основные задачи класса Neuron:
— Реакция на входной сигнал
— Суммирование
— Корректировка
(как дополнительно можно добавить чтение из файла, создание начальных значений, сохранение. Оставим это на «совести» читающих)
Переменные внутри класса Neuron:symbol
— Идентификатор «опознания» — LastY
— Описываемый образ — symbolsymbol
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется